这次阅读发布在《Nature》上的《Mastering the game of Go with deep neural networks and tree search》,正是 AlphaGo的论文。当时 AlphaGo 在击败欧洲冠军职业二段樊麾后,引起了业内不小的轰动。
本人从小学开始进行系统化象棋训练,二十多次斩获中国象棋比赛个人奖杯以及队制奖杯。除此以外,对国际象棋也颇有成就,ELO 的分数大约在 1300 浮动,拿过学界亚军和 Board Prize。
至于围棋自幼便听闻,琴棋书画四艺的棋指的正是围棋,却因接触象棋更为早,惯性地就选择了象棋系,后来更是对走法规则接近的国际象棋也产生了兴趣。
我在 2012 年第一次参加国际象棋比赛,一开始和象棋引擎对战练习。国际象棋领域内机器一早就赢过人类多次了,IBM 深蓝早在十五年前以微弱优势击败了老棋王卡斯帕罗夫[1],直到八年后才能确认机器在国际象棋完全超越最顶尖的人类选手。后来随着技术进步,开源的象棋引擎 Stockfish 脱颖而出[2],技术上比深蓝的暴力搜索更为简洁和有效率。写这篇文章时,翻了翻他的更新日志,更到了 v12 ,新增了神经引擎模块,比上一代胜率高 10 倍。因此,对围棋不熟悉以及对人工智能发展状态的陌生,我一直以为计算机早早攻克了所有棋类。
后来的故事,大家都非常清楚,出乎意料,AlphaGo 4-1 击败了围棋最强者之一李世石。
作为一个象棋选手,我没有因此感到很绝望或者不舒服,我更是惊讶于围棋对象棋引擎的挑战性,「竟然还没攻克」。
人不敌与机器在象棋里早早就发生了。一开始,大家可能很慌张,觉得人类在此事上已经没有了钻研的意义了。然而,象棋引擎带来的却是人类整体水平的大幅提升。现在,从顶尖职业棋手到小孩子,都使用象棋软件来训练自己。通过象棋引擎的分析,出现了很多从未被想到的下法。
地球上跑得最快的男人——保特,我们尊敬他一次又一次突破了人类自身的生理极限。我们从不要求他猎豹、雄狮跑的更快,也不会让他和特斯拉比 100 米。同样地,为什么要以这样的标准要求围棋选手呢?
或许,AlphaGo 打开了围棋新世界的大门,让这个悠久历史的运动重焕青春。
围棋基本规则
- 黑白两方交替走棋
- 棋盘大小是 19,棋子一共能放在 $19 \times 19 = 361 $ 个节点上
- 和象棋不同,围棋落子后不能移动
- 通过计算棋子所占区域大小判断胜负
- 吃子规则是把对方棋子相邻交叉点围住就能吃掉,故得名围棋
因为象棋棋子能移动,棋谱的每一步是记录棋子的移动。中国象棋记录棋谱形式有点像汇编语言里的 mov source,dest ,为「子名——原始列——动作(进/平/退)——目的位置」。例如,常见中炮局第一步为炮二平五,意思就是炮从红方第二列走到第五列。和中国象棋走法接近的国际象棋记录方式大同小异。
| 步数 | 红方 | 黑方 |
|---|---|---|
| 1 | 炮二平五 | 马8进7 |
| 2 | 马二进三 | 车9平8 |
| 3 | 车一平二 | 马2进3 |
| 4 | 兵七进一 | 卒7进1 |
| 5 | 车二进六 | 炮8平9 |
以上摘自广东吕钦胜上海胡荣华前五步。
与象棋不同,围棋棋子不用移动,所以棋谱记录方式为一个时间序列,在棋盘的交叉点上标记黑/百以及步数,则能完整记录对局。
当前局面能用状态向量 $\vec s$ (代表 state)表达,361 个节点的每个节点在某一刻都有三种状态,分别是 1|0|-1 ,对应白、黑、空。
$$
\vec s = (\underbrace{1,0,-1,\ldots}_{\text{361}})
$$
表示要走的步可以表达为 action 向量 $\vec a$ ,形如 $\vec a = (0,\ldots,0,0,1,\ldots)$。要注意的是,围棋坐标系使用笛卡尔坐标系,x 轴为英文字母 a-s,纵轴为阿拉伯数字 1-19。为了简单运算,在文章里将 x 轴也以 1-19 指代,映射到英文字母 a-s。从 1 开始算起,而不是计算机的 0 开始算起,因此:
假设 1 在第 4 个位置, $\vec a = (0,0,0,1,0,0,\ldots)$ ,表示在棋盘的 1 行 4 列下棋。
假设 1 在第 40 个位置, $\vec a = (0,0,\ldots,1,0,\ldots)$ ,表示在棋盘的 3 行 2 列下棋。
归纳得知,根据坐标棋盘的行列坐标 $(r,c)$ , 1 在的 $\vec a$ 位置为 $19\times(r-1)+c$ 。
因此棋盘局面状态是 $\vec s$ ,走棋是 $\vec a$ ,给定任意状态 $\vec s$ ,AlphaGo 要给我一个最优策略 $\vec a$ ,从而在 361 个节点填满后,获得最大地盘。
为什么要攻克围棋?
The game of Go is the Holy Grail of Artificial Intelligence.
围棋是人工智能的圣杯
围棋是公认人工智能的噩梦,因为状态空间非常大,达到了 $2 \times 10^{170}$。暴力枚举不可取,以计算机目前的算力,就算把所有电脑集合在一起,也无法把所有可能出现的局面穷举。要在不让子的情况下战胜顶尖棋手,需要使用更有效率的方法来实现。
显然,人类无法暴力搜索,也能下好围棋(当时没有引擎能不让子赢职业棋手),是因为人类能把局面抽象出来。大部分时候,没有一套规则给棋手按着走就能赢,而是通过玄乎的「感觉」,顶尖棋手有时候很难说出来下这棋的原因,这是日积月累训练培养出来的直觉。这正是过往象棋引擎难以攻克围棋的原因,围棋规则虽则简单,胜负判断却难以具体描述。
Learning is the key thing here. It’s machine learning.
AlphaGo 就是要把这种模糊的棋感模拟出来,最终击败人类。
技术实现
AlphaGo 是一个「缝合怪」,他在每一个阶段所做的都是在业界内已经有人做过了的。他的创新在于把这些不同的方法巧妙融入到一个框架内,并让它达到从没有人做到的地步——战胜最强职业棋手。无论是深度神经网络,还是强化学习,都只是为了用来搜寻最好的下法。
- 监督学习:使用人类在专业比赛的对战数据做有监督学习
- 蒙特卡洛树模拟
- 估值网络
- 强化学习:自我对弈
监督学习——师夷长技以制夷
AlphaGo 第一步要学习人类下棋套路。
CNN 卷积神经网络
通过输入人类 $19\times19$ 棋谱照片,建立深度卷积神经网络( Deep Convulutional Neural Network,下称 CNN)。因为是围棋,估计使用一个 channel 的灰阶照片就足够了,棋谱照片能被一个二维矩阵所代表。
CNN 可以帮我们提取图像中有意义的特征,日常生活的文字识别、图像物品识别都有用到 CNN(例如 iOS 照片 App 能识别出海滩、草地、船、食物等标签)。举例,一个训练好的神经网络,输入是一个船的照片,输出形如 dog(0.01), cat(0.01), boat(0.94),通过哪个概率最高。
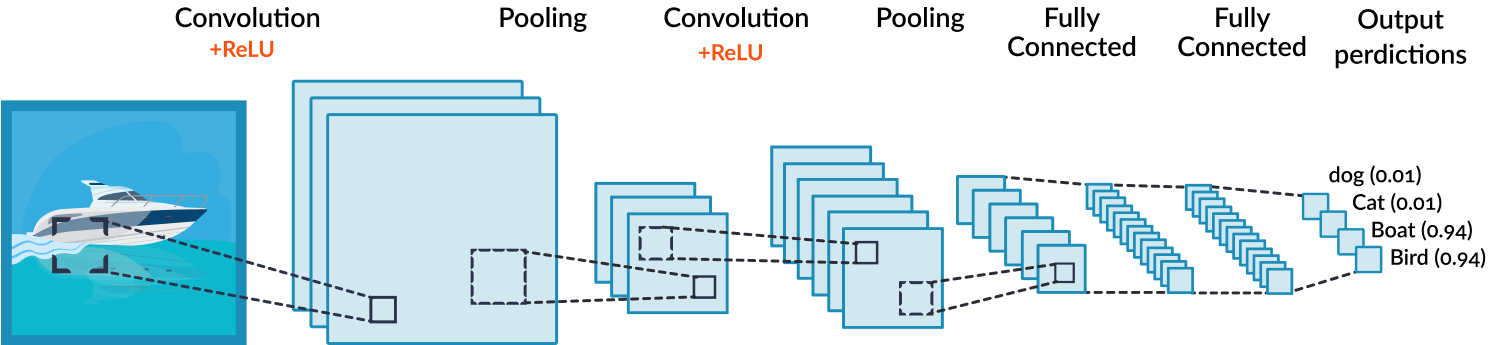
现实世界大多东西都是非线性的,所以我们要让图片变得非线性,图中使用了 Rectified Linear Unit (RELU),表达式为:
$$
Output=\max(zero,Input)
$$
为了进一步简化特征的非线性关系,文章里提到使用一部分围棋理论作为输入,我对围棋原理不算熟悉,这里就不多说了。

棋盘局面状态是 $\vec s$ ,走棋是 $\vec a$ ,给定任意状态 $\vec s$ ,AlphaGo 要给我一个最优策略 $\vec a$ ,从而在 361 个节点填满后,获得最大地盘。
网络时代诞生的网上围棋对战平台产生了大量棋谱,第一作者 Aja Huang 利用网上公开的十六万个棋谱[3],在海量的 $\vec s$ 局面下,每一个局面都有一个人类对应的行为 $\vec a$ ,一共三千个万组 $<{\vec s},{\vec a}>$。CNN 就能通过训练数据以及一些额外的围棋参数(e.g. 气)进行有监督学习。因此,概括来说,是这样:
输入:
- $\vec s$ ,棋盘图像(图像本质是矩阵,拍扁就是一个向量)
- 围棋理论,上面的图
- $\vec a$ ,棋谱里人类的下法
输出:
- 输出 $\vec a$ 的概率
输出是一个概率分布,参考船的 CNN 例图,概率最高的那个就是神经网络认为最接近人下法的 $\vec a$ 。
因此,输入和输出可以建立为映射关系的函数,这个函数叫 Policy Network(策略函数),存在局面 $\vec s$ ,CNN 输出一个落子概率分布,取最大概率,得到 $\vec a$。这个函数记为 $P_{}$。
$P$ 对人类下棋的预测准确率达到 57%,当时世界其他顶尖研究团队大约处在 44%。不过 $P$ 有个问题,他的神经网络大小过大,虽则精确,可是速度太慢,做一个预测需时 3ms。Deepmind 为此做了个瘦身的 $P_{lite}$ 版本,将耗时降到 2μs,时间节省为 1000 倍,不过准确度下降到 24.2%。
为什么棋力不足
即使是完整网络 $P$ ,棋力和人类本身差了一大截。
第一,训练样本大多是业余棋手的棋谱,学习预测都是业余棋手的下法,而业余棋手棋力不高。
第二,就算有职业棋手的棋谱,数量级过小,不足以大幅提升函数的棋力。这主要是因为职业选手太少了,顶尖的更是屈指可数。
第三,Policy Network 的本质是学习然后预测,而人类下棋有时候下好的,有时候也有臭棋,这个网络赢棋的下法学习,导致崩盘的下法也学习
第四,和第三点有点不同的是,赢棋的下法也不一定是好棋,类似在国际象棋里,有时候赢棋只不过是因为对手表现更逊色一筹,并不是我下的好,俗语说:全靠同行衬托。
估值网络
我们知道 SL 有监督学习之所以叫有监督,是因为有标签,告诉神经网络「正确答案」。
在前一节,在一对 $<{\vec s},{\vec a}>$ ,$\vec s$ 是特征,$\vec a$ 是标签,给定一个局面 $\vec s$ ,CNN 应该尽量给一个概率最高的 $\vec a$ 。
然而,正如上面解释为什么棋力不足, $\vec a$ 和局面的输赢并不相关。现在我们要建立一个估值网络,而这是和输赢相关的,所以我们要修改标签的定义。
增加一个标签关于赢、输、和(用 1、-1、0 来代表),对应的特征是 $\vec s’$ ,代表在 $\vec s$ 走 $\vec a$ 产生的心得局面,即 $\vec s’=(\vec s,\vec a)$ 。
因此新的一组训练数据长这样:$<{(\vec s,\vec a)},{\vec z}>$ 。三个向量都是有记录的历史数据,所以我们仍然能训练。
很自然地,我们会想到使用之前 CNN 训练的那 3000 万个训练样本,再扔到这个估值网络去跑。Deepmind 就是这样想的,最终结果和之前过度相似。这个原因可以归纳成上文所说的臭棋能决定性地影响局面。
Deepmind 利用 self-play,生成了 3000 多万个 $<{(\vec s,\vec a)},{\vec z}>$ ,而且每个 $\vec s$ 都来自不同盘棋,意思就是一共有 3000 多万个棋谱,对比之前人类棋谱是 16 万盘。这样一定程度上防止了臭棋的 strong correlation。
这次,带了 $\vec z$ 的函数就叫做 Value Network,记为 $v$ , 输出该局面胜负概率 $v(\vec s)$。
对比 Policy Network 输出的是预测这步棋人类会下的概率,Value Network 输出的是胜率。
Policy Network 使用 max 函数去挑人类最可能走的棋作为 $\vec a$ ,而 Value Network 则不然。他将下一步走棋产生的新局面 $\vec s’$,作为参数传入 $v(\vec s’)$ ,求走不同棋导致胜率的分布,最后选取胜率最高的那步棋作为下一步要走的棋。
强化学习——左右互搏
AlphaGo 纪录片的开头,正是 Demis Hassabis 在大学里演讲,说明如何利用强化学习来训练,让他玩 Atari Breakout(经典游戏,可以理解为 Pong 的单人版)。很快强化学习模型就学会了怎么在上方弄条隧道,让球自己在上面不断来回碰撞。

通过自我博弈,能让神经网络的棋力更大提升,强化学习后的 Policy Network 对上原始 Policy Network,胜率大约是八成。不过因为走棋单一,所以对上人类棋手,反而不如原始版,留意下文「a diverse beam of promising moves」:
It is worth noting that the SL policy network $p$ performed better in AlphaGo than the stronger RL policy network $p_{rl}$, presumably because humans select a diverse beam of promising moves, whereas RL optimizes for the single best move.
不过,强化学习的好处是能够提供更多高质量样本给我们的估值网络进行训练。实验数据得出,利用增强学习后的 Policy Network 去训练 Value Network,效果更佳。(相对于利用原版 Policy Network 去训练 Value Network)
蒙特卡罗树搜索
论文的标题 「tree searches」 侧面反映了蒙特卡罗树搜索的重要性。
Rollout
Monte-Carlo Tree Search(MCTS)核心思想是随机。通过双方(都是电脑)随机下棋,以及后来的胜负,能得知某一个局面 $\vec s$ 下,走哪步棋会导致赢。在不停地随机训练后,陌生局面就会越来越少。(我看网上有人分析说李世石 God Move 78 或许就是走了陌生局面)
经过内部很多的调整,以及理论的迭代,Aja Huang 最终拿出了以下方式:
$$
\text{新分数} = \text{调整后的初始分} + \text{通过模拟的赢棋概率}
$$
调整后的初识分与 Policy Network 相关。所以一开始随机走,会使用人类下棋作为基准,随着随机模拟量的增多,走出更多人类没走过的走法,最终达到一个新的棋力水平。
后来因为 Policy Network 完全版太 bulky,所以选择用上前面说到的瘦身版,速度快了 1000 倍。
感想
在阅读这篇论文以及对其的解读,觉得设计实在是太精妙了,不时有那种 Eureka Moments——「还能这样!」。作为人工智能初学者,一开始读论文实在是太难了,只好找各种给小白的解说,后来慢慢知道了一个个不同的概念还有一些重要函数的公式,再以这些作为关键字扔到 Google 里看更多的资料。相比一个多礼拜前的自己,能明显感觉到确实对原理理解多了很多。或许这也是类似 Machine Learning 吧,让自己输入大量的资料,渐渐迭代以及学习出比之前更强的自己。
有很多部分,并没有很详细地写出来,一来是没有透彻掌握,写多错多,二来也不想误导其他读者。
Engineering is the closest thing to magic that exists in the world.
非常感谢网上公开的资料,正如 Elon Musk 说过在现今互联网知识开放的时代,你能免费地学任何东西。如果没有以下的参考资料,我或许是自闭地看文章而毫无头绪。最后,也推荐一下 AlphaGo 的纪录片,很紧张地描述了当时 Deepmind 团队的心情,他们也不知道能否创造历史,在巨大的压力中安全度过。
如果你们有什么想法的话,欢迎在下方评论区交流以及指正我的错误。
参考资料
- AlphaGo - The Movie | Full Documentary
- 读《Nature》论文,看AlphaGo养成
- 「戰勝自己」不只是口號──《Nature》AlphaGo論文讀後感
- 深入浅出看懂AlphaGo如何下棋
- An Intuitive Explanation of Convolutional Neural Networks
- A Quick Introduction to Neural Networks
- Move Evaluation in Go Using Deep Convolutional Neural Networks
- 什么是强化学习 - 莫烦
卡斯帕罗夫和深蓝分别在 1996 和 1997 年对战了两次。第一次卡斯帕罗夫以大分 4-2 击败深蓝;第二次深蓝以大分 3.5-2.5 击败卡斯帕罗夫。 ↩︎
赢了第6赛季(2014年)、第9赛季(2016年)、第11赛季(2018年)、第12赛季(2018年)、第13赛季(2018年)、第14赛季(2019年)、第16赛季(2019年)、第18赛季(2020年)和第19赛季(2020年)的非官方世界计算机国际象棋冠军。在第5季(2013年)、第7季(2014年)、第8季(2015年)、第15季(2019年)和第17季(2020年)则获得亚军。 ↩︎
从围棋对战平台 KGS 上获得的 3000 万个样本 ↩︎